




![]()
Pressemeddelelse fra Alexandra Instituttet

De mange termer der beskriver forklarlig kunstig intelligens (explainable AI)
Vi anvender kunstig intelligens på stadig flere områder, og beslutninger baseret på kunstig intelligens kommer tættere på at påvirke vores privatliv. I den forbindelse er der dukket mange begreber op, som explainable (forklarlig) kunstig intelligens, interpretable (fortolkbar) maskinlæring, transparent kunstig intelligens og intelligible (forståelig) kunstig intelligens. I figuren nedenunder kan du se udviklingen i Google-søgninger på ‘Explainable Artificial Intelligence’ og ‘Interpretable Machine Learning’ op til 2019.
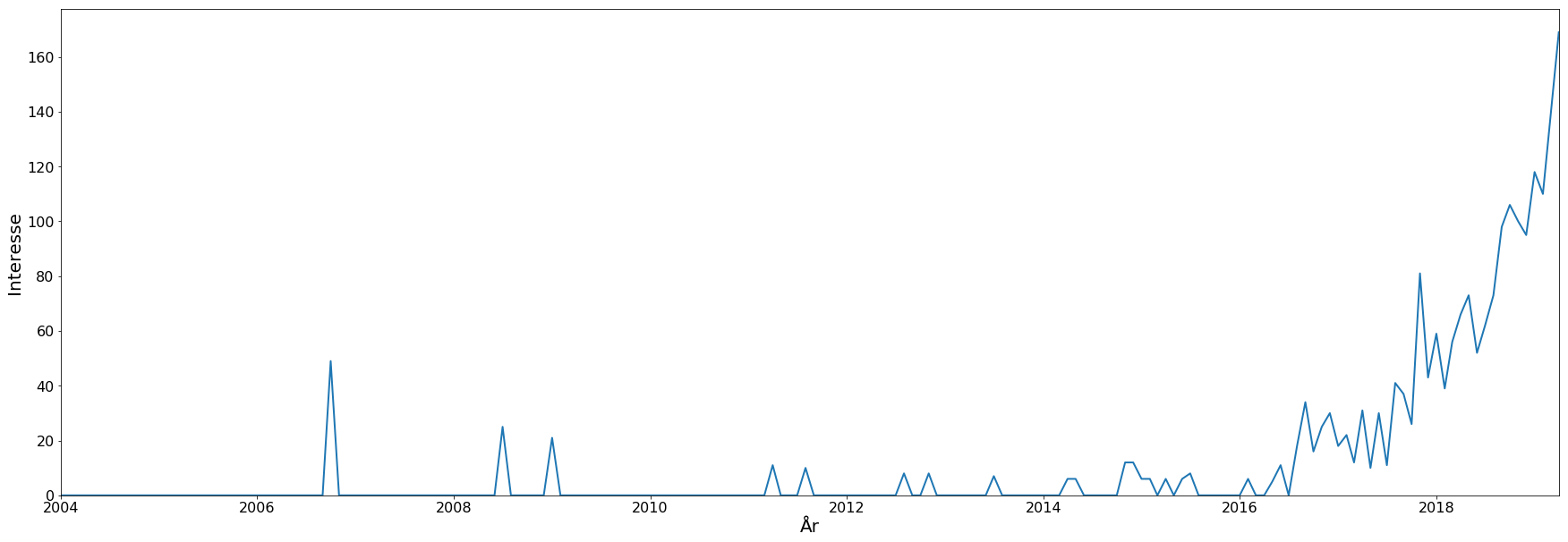
Google Trends over hele verden på “explainable AI” og “interpretable ML” op til 2019 (Data kilde: ).
Men hvad er egentlig meningen bag de begreber, og hvordan definerer man forklarlighed? Vi starter med at prøve at definere forklarlighed baseret på ordbogsdefinitionen af “at forklare”, som skaber grundlag for begreberne inden for forklarlig kunstig intelligens.
Senere i blogindlægget kan du læse om, hvilke egenskaber en model skal have, for at vi kan kalde den forklarlig, ud fra de definitioner vi kommer ind på nu.
Definition
Når man kigger i ordbogen, kan man finde følgende definition af ““:
gøre noget klart for andre ved at beskrive, oplyse eller på anden måde fortælle nærmere om det
angive en årsag eller grund til noget; gøre rede for noget
Baseret på den engelske definition har Doshi-Velez et al.¹ defineret “interpretability” i konteksten af kunstig intelligens på den følgende måde:
“the ability to explain or present in understandable terms to a human” (evne til at forklare eller præsentere på en forståelige måde til et menneske)
Med andre ord kan forklarlighed ses som en interface mellem en model og brugeren af modellen, der forklarer modellen eller dele af modellen til brugeren. Det er dog ikke tydeligt, hvordan “evne til at forklare” er defineret, og hvad “på en forståelig måde” betyder fra et teknisk perspektiv, da forklarlighed eller gennemsigtighed er afhængig af målet, og hvem eller hvad det er målrettet til. Der findes derfor ikke en enkelt definition af forklarlighed, men til gengæld findes der mange nuancer betinget af konteksten og målet.
Derfor vil vi nu præsentere de forskellige kontekster og målgrupper, som typisk er i spil i forhold til forklarlig kunstig intelligens, så vi kan nærme os en mere konkret og anvendelig definition, man kan tage udgangspunkt i, når vi udvikler kunstig intelligens.
Forskellige mål af forklarlighed
Som regel er datadrevne modeller, der er lavet ved (supervised) maskinlæring, evalueret gennem metrikker (se en på og ), der sammenligner “eksempel-data”, man ved, der er rigtigt, med modellens forudsigelse. Men der er andre faktorer, man også kan evaluere modellen på, og der påvirker modellens værdi eller omkostninger, når modellen er sat i drift, f.eks. tillid, informationsindhold, opretholdelse af etik, osv. Det er tit ikke muligt til at definere metrikker, der måler disse faktorer, så den eneste løsning til at evaluere dem er gennem forklarlighed. Vi vil nu beskrive de mest almindelige mål og faktorer af forklarlighed, også kaldet “desire-data”², såsom tillid, fairness og etik, information, transfer af viden, debugging og monitorering. Flowcharten herned guider dig igennem disse mål af forklarlighed og hvilke målgrupper der er tilknyttet.
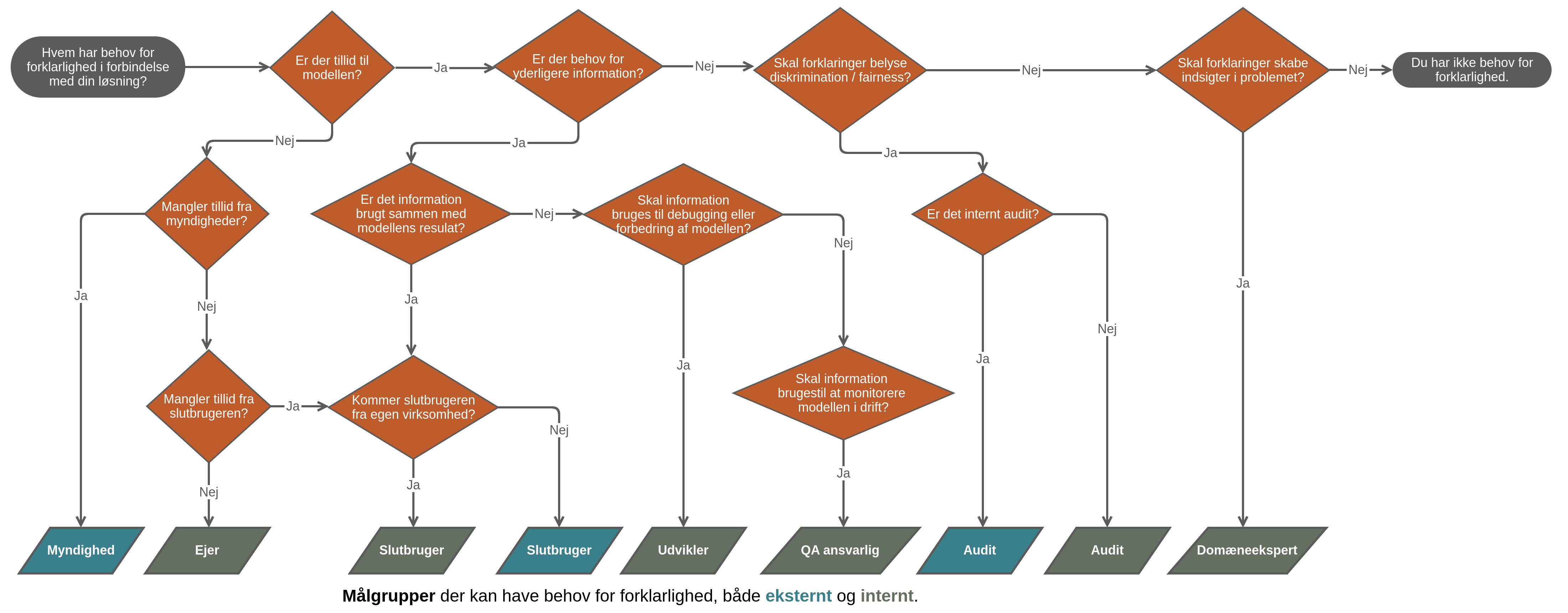
Flowchart der igennem mål af forklarlighed og hvilke målgrupper der er tilknyttet.
Tillid
Tillid til en model er vigtigt, for at slutbrugerne faktisk bruger modellen og agerer på dens resultater og anbefalinger. Tillid kan have forskellige former: 1) Tillid til at modellen virker. Her kan det være nok at bruge almindelige metrikker til at vise modellens evner. 2) Det kan også være tillid til, at modellen virker i drift. Det vil sige viden om, hvordan modellen opfører sig i nye, ukendte scenarier og viden om modellens styrker (hvornår virker det?) og begrænsninger (hvornår virker det ikke?).
Det er tit ikke muligt at definere trænings- eller testdata, der dækker alle eksisterende og mulige kommende scenarier, og det er derfor kun muligt at måle modellens nøjagtighed på scenarier beskrevet i dataene. I andre situationer kan der opstå såkaldt “concept-drift”, altså at sammenhænge i data ændrer sig og afviger fra de data, modellen blev trænet på, efter modellen er blevet sat i drift. I begge tilfælde vil det øge tilliden til modellens performance i uforudsete omgivelser, hvis man kunne forstå eller forklare, hvordan modellen virker.
Fair og etisk
Afhængigt af konteksten, hvori modellen er brugt, kan der kræves bestemte etiske standarder (f.eks. ), og nogle gange endnu et bevis på det lovmæssige ansvar. Den europæiske GDPR, for eksempel, beskriver, at en person, der er påvirket af en automatisk beslutningsproces, har mulighed for at få “meningsfulde oplysninger om logikken” (), og at dem, der ejer modellen, skal sørge for “passende foranstaltninger til at beskytte den registreredes rettigheder” (). Hvad meningsfulde oplysninger er, og i hvilken grad det handler om forklarlighed, er der dog debat om³ â´ âµ. Men uanset hvad, så er det sikkert, at forklarlighed i den rigtige form vil hjælpe med at vurdere om etiske, fair og lovmæssige krav er opfyldt eller forklarlighed kan være en måde til at opfylder dem direkte.
Informationsindhold
Især når en model interagerer med en ikke-teknisk slutbruger, og når modellen er brugt til beslutningsstøtte, kan yderlige information om hvordan en model virker, og hvorfor den er kommet med et bestemt resultat være vigtigtâ¶. Det kan blive relevant, når modellens output kun er en del af en beslutningsproces, eller hvis modellens resultater skal forklares videre af brugeren til en anden person.
Forestil dig for eksempel at du spørger en læge, hvilken behandling der vil virke bedst på en bestemt sygdom, du har. Det er slet ikke nok bare at få navnet at vide eller beskrivelsen af behandlingen – du vil også være interesseret i hvorfor, det er den bedste behandling, hvad der er af alternativer, og om der er nogle risici. I dette tilfælde kræves der flere informationer for at træffe en god beslutning.
Overførsel af viden
Fordi modellen opbygger “viden” om et problem eller en repræsentation af en løsning (baseret på data), kunne det være interessant at overføre denne viden til et menneske eller en anden maskine (model). Kun hvis vi forstår modellens beslutninger eller forudsigelser og evnen til at kunne forklare disse, er det muligt at overføre viden på en måde.
Overførsel af viden kan også være en vigtig faktor til modellens værdi eller brugbarhed. Selvom modellen er trænet og testet på forskellige data, for at vise evnen til at modellen kan generalisere godt på nye data, blev det vist, at en models resultat kan manipuleres ved små ændringer i inputdataene (Intriguing properties of neural networks). Modellerne, der kan overføre viden og opbygge kausalitetssammenhænge i stedet for “bare” at finde korrelationer, kunne være bedre beskyttet imod disse angreb.
Debugging
Forklaringer kan være et yderligere værktøj til at finde nye strategier til at forbedre og debugge en model, f.eks. til at finde ud af hvorfor modellen virker dårligt på bestemte eksempler i dataene eller som hjælp til at fjerne unødvendige inputvariabler.
De kan også bruges til at verificere, at modellen “kigger” på de rigtige ting, og at den ikke har lært mærkelige korrelationer i data, som for eksempel at finde skibe i et billede på grund af at der er vand, men ikke på grund af skibet, eller at genkende heste på grund af et vandmærke i stedet for hestenâ·, eller at forudsige en lavere risiko til at dø af lungebetændelse når man har astmaâ¸. Ifølge en ny undersøgelse er debugging eller et såkaldt “sanity check” det mest brugte mål af forklarlighed i praksis i øjeblikketâ¹.
Monitorering
Som beskrevet tidligere er almindelige performance-metrikker ikke altid nok til at måle en models værdi eller omkostning løbende i driftssituationen. Det er dog disse metrikker, der bliver brugt til at monitorere forskellige modeller og deres performance. Her kan forklaringer være en yderlige “performance”-metrik til at identificere en model-“drift”¹â°.
Egenskaber hos forklarlige modeller
Efter at vi nu har etableret de forskellige mål af forklarlighed, er det næste spørgsmål hvilke egenskaber en forklarlig model skal have. R. Guidotti et al. beskriver tre forskellige egenskaber: interpretability (forklarlighed), performance og fidelity (troskab)¹¹. Der findes andre egenskaber, ligesom fairness, sikkerhed og, brugbarhed, men disse er ikke nødvendigt specifikke for forklarlige modeller og kan også delvis adresseres af de andre tre egenskaber.
Forklarlighed
Det kommer ikke som nogen overraskelse, at forklarlige modeller skal være forklarlige. Der kan være forskellige former af forklarlighed (det kommer vi nærmere ind på i et senere blogindlæg), men det er ikke klart defineret, hvordan man skal måle forklarlighed. Doshi-Velez et al. foreslår tre forskellige måder: applikationsbaseret, metrikbaseret på mennesker, tekniske metrikker¹.
Den første, den applikationsbaserede måde, er den mest ressource- og tidskrævende, men også den mest præcise. Her bliver forklarlighed målt, mens modellen reelt bliver anvendt (i driftssituationen). Man måler selve gevinsten af modellen i form af forretningsmetrikker, eller om det er nemmere at identificere fejl, om man genererer ny viden, eller om der er mindre diskriminering. Som basis kan man sammenligne metrikker med menneskelig beslutningsstøtte.
Den anden måde er uafhængig af selve konteksten eller applikationen og fokuserer udelukkende på, hvor godt et menneske forstår modellen. Det kan man måle gennem forskellige forsøgsopsætninger¹² ¹³ ¹â´, for eksempel:
- Man viser forskellige forklaringer, og forsøgsdeltageren vælger, hvilken af dem de bedst forstår.
- Man viser en forklaring samt et input, og forsøgsdeltageren skal gætte, hvad modellens resultat vil være¹âµ. Jo mere rigtigt, de ligger, jo bedre er forklaringen.
- Man viser en forklaring, et input-eksempel og modellens resultat, og forsøgsdeltageren skal beskrive hvilke dele af eksemplets input, der skal skiftes for at ændre modellens resultat. Jo mere rigtigt, de ligger, jo bedre er forklaringen.
Den sidste måde er den mindst ressourcekrævende og mest brugte i litteraturen¹â° ¹â¶ ¹â· ¹â¸. Her bruger man rent tekniske metrikker. Ideen er, at hvis man ændrer et input på de variabler, der bliver fremhævet af forklaringer, så burde modellens nøjagtighed ændres. Dette kan måles gennem almindelige performancemetrikker, men der er forskellige måder at “ændre” inputtet på¹â°.
Performance
Det vigtigste formål med modellen er stadig at lave en nøjagtig prædiktion. Derfor er performance også en vigtig egenskab. Performance måles som regel med forskellige metrikker (se en og ), som f.eks. nøjagtighed. Tit kan der være et trade-off mellem performance og forklarlighed, da simple modeller, som beslutningstræer eller lineære modeller, er mere gennemskuelige men kan ikke modellere komplekse sammenhænge i data. Så den endegyldige beslutning om, hvilken model der virker bedst, er afhængig af balancen mellem de to egenskaber.
Man kan også måle performance i form af det overordnende mål, f.eks. øget brugertilfredshed, bedre behandling af patienter, mere effektive og hurtigere processer, øget omsætning, osv. Forklarlighed kan have en positiv effekt på denne type af metrikker, hvor klassiske metrikker ikke er gode nok til at beskrive performance i forhold til det overordne mål¹â¹.
Troskab
Nogle forklarlighedsmetoder bygger en model til at erstatte black-box-modellen, hvor black-box-modellen er brugt til prædiktioner og den anden model, også kaldt ’surrogate model’, til at generere forklaringer. Men sidstnævnte model skal virke på samme måde som den originale black-box-model, altså generere prædiktioner så tæt som muligt til black-box modellens prædiktioner. Hvis det ikke er tilfældet, så forklarer denne model ikke black-box-modellen, men kun sig selv. Selvfølgelig vil surrogate modellen altid være forskellig, dvs. har en ringere performance en black-box modellen, da man ellers kunne erstatte black-box modellen fuldstændig med surrogate modellen. Troskab måler, hvor tæt forklaringsmodellens resultater ligger på resultater fra black-box modellen.
Konklusion
Bekymringer om forklarlighed vedrørende systemer baseret på kunstig intelligens er ikke nyt, se f.eks. ekspertsystemer²â°, case-based reasoning²¹ (for et historisk overblik se afsnit “Explanation in Artificial Intelligence Systems: An Historical Perspective” i ). Men fordi modellerne er blevet mere komplekse (især dybe neurale netværk) og kunstig intelligens bliver brugt mere til kritiske beslutninger og af ikke-ekspert-brugere, er udfordringerne med forklarlighed mere aktuelt en nogensinde.
Udfordringen ligger i at definere, hvad man egentlig mener med forklarlighed, og at det nu også er nødvendigt at måle modellens performance på mere beskrivende måder – såsom tillid eller fairness.
I dette blogindlæg er vi kommet ind på hvad forklarlighed betyder, hvad man kan opnå med forklarlige modeller, og hvorfor forklarlighed er et vigtig yderlige performancekriterium.
[1] F. Doshi-Velez og B. Kim, “Towards a rigorous science of interpretable Machine Learning”, , 2017.
[2] Z. C. Lipton, “The Mythos of Model Interpretability”, , 2017.
[3] G. Malgieri og G. Comandé, ““, International Data Privacy Law, pp. 243-265, 2017.
[4] S. Wachter, B. Mittelstadt og L. Floridi, ““, International Data Privacy Law, pp. 76-99, 2017.
[5] A. Selbst og J. Powles, ““, International Data Privacy Law, pp. 233-242, 2017.
[6] B. Y. Lim og A. K. Dey, ““, Proceedings of the UbiComp ’09, pp. 195-204, 2009.
[7] S. Lapuschkin, S. Wäldchen, A. Binder, G. Montavon, W. Samek og K.-R. Müller, ““, Nature Communications, 10, 2019.
[8] R. Caruana, Y. Lou, J. Gehrke, P. Koch, M. Sturm og N. Elhadad, ““, Proceedings of KDD ’15, pp. 1721-1730, 2015.
[9] U. Bhatt, A. Xiang, S. Sharma, A. Weller, A. Taly, Y. Jia, J. Ghosh, R. Puri, J. M. F. Moura og P. Eckersley, ““, Proceedings of FAT* ’20, pp. 648-657, 2020.
[10] S. M. Lundberg, G. Erion, H. Chen, A. DeGrave, J. M. Prutkin, B. Nair, R. Katz, J. Himmelfarb, N. Bansal og S.-I. Lee, ““, Nature Machine Intelligence, 2, pp. 56-67, 2020.
[11] A. Weller, “Challenges for Transparency”, , 2017.
[12] J. Chang, S. Gerrish, C. Wang, J. L. Boyd-Graber og D. M. Blei, ““, Advances in Neural Information Processing Systems 22, 2009.
[13] T. Kulesza, M. Burnett, W.-K. Wong og S. Stumpf, ““, Proceedings of the IUI’15, pp. 126-137, 2015.
[14] F. Poursabzi-Sangdeh, D. G. Goldstein, J. M. Hofman, J. W. Vaughan og H. Wallach, “Manipulating and Measuring Model Interpretability”, , 2019.
[15] M. T. Ribeiro, S. Singh og C. Guestrin, ““, Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[16] G. Montavon, W. Samek og K.-R. Müller, ““, Digital Signal Processing, pp. 1-15, 2018.
[17] M. Ancona, E. Ceolini, C. Öytireli og M. Gross, “Towards better understanding of gradient-based attribution methods for Deep Neural Networks”, , 2018.
[18] A. Shrikumar, P. Greenside og A. Kundaje, “Learning Important Features Through Propagating Activation Differences”, , 2017.
[19] L. Bernardi, T. Mavridis og P. Estevez, ““, Proceedings of KDD ’19, pp. 1743-1751, 2019.
[20] P. Jackson, “Introduction to Expert Systems”, Addison-Wesley Longman, Harlow, 1990.
[21] A. Kofod-Petersen, J. Cassens og A. Aamodt, ““, Proceedings of SCAI 2008 , pp. 28-35, 2008.
Kontakt:
Communications Specialist Lisa Lorentzen tlf.: +45 93 52 17 64 email: lisa.lorentzen@alexandra.dk
Læs hele pressemeddelelsen på Via Ritzau her: https://via.ritzau.dk/pressemeddelelse/hvad-betyder-forklarlighed-nar-vi-taler-om-kunstig-intelligens?releaseId=13593240
** Ovenstående pressemeddelelse er videreformidlet af Ritzau på vegne af tredjepart. Ritzau er derfor ikke ansvarlig for indholdet **


